Added Context: The most cited papers ever
by Ryan Pevey
Added Context is a recurring series where I revisit headlines, stats, and science news stories that could use a little more nuance; adding a fresh visualization or a bit of extra context to make the numbers easier to explore. Think of it as a friendly data companion to the headlines.
What are the top cited scientific papers of all time?
Nature recently published a list of the most cited scientific papers all time and it’s making the rounds on social media. An impressive roundup of highly influential work, based on the Web of Science citation data. Its actually a follow up to a previous version of the list that they made back in 2014, when they created a beautiful infographic to accompany it, offering readers an immediate, visual sense of the trends behind the numbers.
Looking at the list, there’s some real bangers on here if you’ve published basically anything in biology. Even if you haven’t cited some of these you’re probably familiar with the works.
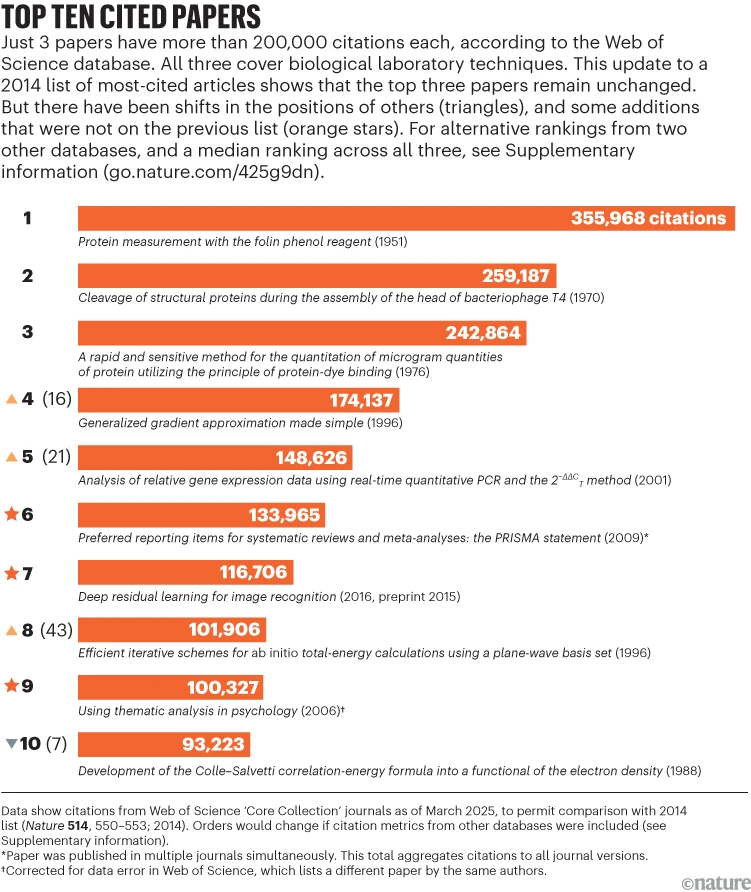
Fig. 1: Nature’s new Top 10 cited papers of all time (2025) according to the Web of Science database.
Most cited papers of the 21st century
They also published a list of the most cited papers of this century so far. The previous list was dominated by biology technique papers and they’re still there. Those papers are joined by machine learning and psychology. This time around though, we only got a table. So let’s fix that. I’ve followed some of the stylistic choices of their other plot above, with some minor tweaks for my own eye. The blue bar represents the highest and lowest recorded number of citations within the five datasets. Overall, the trend seems to match expectations in the figure but I think this highlights how much variability there is between the datasets. Especially where the machine learning and AI focused papers seem to have higher variability in the range of documented citations.
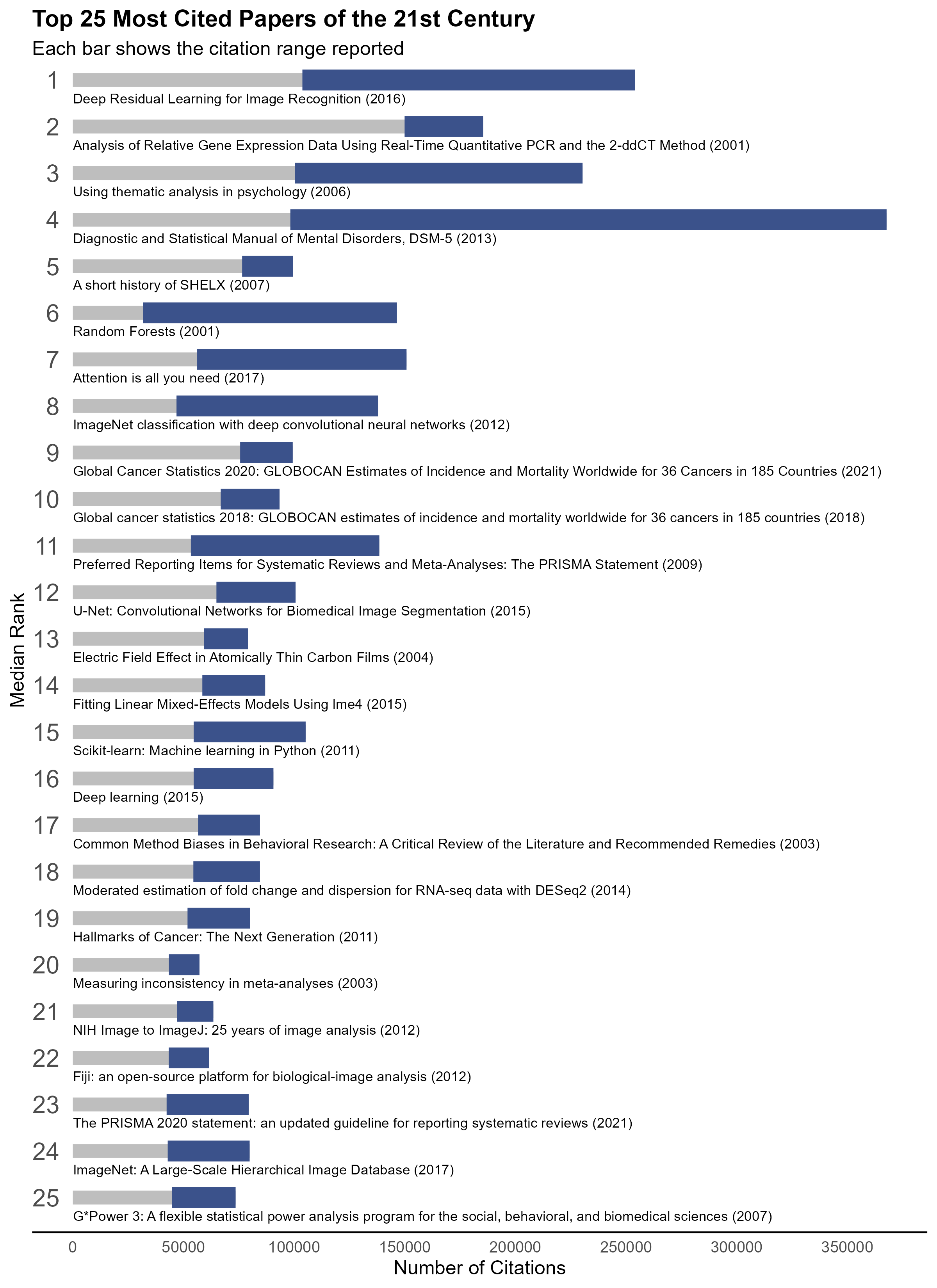
Fig. 2: Citation ranges for top 25 most cited papers of the 21st century.
We can also use their data to see what the differences are between the five different databases they used for this analysis. The dashed diagonal line is where the papers rank in each database would match their median rank across all five databases. Ironically if you look at the raw number of citations, Google scholar consistently records the highest number of citations across the board, especially for machine learning and AI papers. However, when looking at these papers that seems to translate in lower rankings for each paper as the majority of yellow triangles are below the dashed line. Scopus rankings are the opposite, mostly above the dashed line. I don’t know exactly what to read into that? Maybe, the shear number of Google scholar citations are less biased. Maybe the Scopus database, as arguably the most academic focused, is more siloed or focused on methods papers than the others. Or maybe Scopus is just picking up higher quality papers better than the other four databases. An honorable mention is also that the Web of Science dataset seems to dislike the Random forests paper to a hilarious degree.
Fig. 3: Rankings for the top 25 most cited papers of the 21st century across all five databases.
Here’s the table showing the data that went into creating figure 2, in case you were curious. It recreates the table from the original Nature feature, but mine includes the top 25 papers instead of just the top 10.
Table 1: The highest and lowest recorded number of citations across all five datasets for each paper.
| Rank (median) | Citation | Times cited (lowest) | Times cited (highest) |
|---|---|---|---|
| 1 | Deep Residual Learning for Image Recognition (2016) | 103756 | 254074 |
| 2 | Analysis of Relative Gene Expression Data Using Real-Time Quantitative PCR and the 2-ddCT Method (2001) | 149953 | 185480 |
| 3 | Using thematic analysis in psychology (2006) | 100327 | 230391 |
| 4 | Diagnostic and Statistical Manual of Mental Disorders, DSM-5 (2013) | 98312 | 367800 |
| 5 | A short history of SHELX (2007) | 76523 | 99470 |
| 6 | Random Forests (2001) | 31809 | 146508 |
| 7 | Attention is all you need (2017) | 56201 | 150832 |
| 8 | ImageNet classification with deep convolutional neural networks (2012) | 46860 | 137997 |
| 9 | Global Cancer Statistics 2020: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries (2021) | 75634 | 99390 |
| 10 | Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries (2018) | 66844 | 93433 |
| 11 | Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement (2009) | 53349 | 138534 |
| 12 | U-Net: Convolutional Networks for Biomedical Image Segmentation (2015) | 64905 | 100673 |
| 13 | Electric Field Effect in Atomically Thin Carbon Films (2004) | 59364 | 79165 |
| 14 | Fitting Linear Mixed-Effects Models Using lme4 (2015) | 58535 | 86931 |
| 15 | Scikit-learn: Machine learning in Python (2011) | 54602 | 105225 |
| 16 | Deep learning (2015) | 54602 | 90674 |
| 17 | Common Method Biases in Behavioral Research: A Critical Review of the Literature and Recommended Remedies (2003) | 56616 | 84589 |
| 18 | Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2 (2014) | 54480 | 84589 |
| 19 | Hallmarks of Cancer: The Next Generation (2011) | 51841 | 80093 |
| 20 | Measuring inconsistency in meta-analyses (2003) | 43410 | 57246 |
| 21 | NIH Image to ImageJ: 25 years of image analysis (2012) | 47048 | 63516 |
| 22 | Fiji: an open-source platform for biological-image analysis (2012) | 43315 | 61640 |
| 23 | The PRISMA 2020 statement: an updated guideline for reporting systematic reviews (2021) | 42387 | 79476 |
| 24 | ImageNet: A Large-Scale Hierarchical Image Database (2017) | 42886 | 79921 |
| 25 | G\*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences (2007) | 44803 | 73578 |
Further Reading & References
- Original publication: Pearson, H., Ledford, H., Hutson, M., Van Noorden, R. (2025) Exclusive: the most-cited papers of the twenty-first century. Nature 640, 588, doi: 10.1038/d41586-025-01125-9
- Van Noorden, R. (2025) These are the most-cited research papers of all time. Nature 640, 591, doi: 10.1038/d41586-025-01124-w
- Van Noorden, R., Maher, B., Nuzzo, R. (2014) The top 100 papers. Nature 514, 550, doi: 10.1038/514550a
- Web of Science
Scripts
You can find my github profile here: My GitHub profile.
Open data fuels open science.
Stay Connected
If you’re a student, researcher, or just a science enthusiast, I’d love to hear your thoughts. Reach out or follow along via RSS for more deep dives into brain research, data storytelling, and big data reanalysis.
Leave a comment